Dlaczego „era kubitów” zaczyna się wcześniej, niż działają idealne komputery kwantowe
Od hype’u do realnej dostępności: komputery NISQ
Komputery kwantowe już istnieją, ale są to maszyny z epoki NISQ (Noisy Intermediate-Scale Quantum). Oznacza to, że mają ograniczoną liczbę kubitów, są podatne na szum i błędy oraz nie posiadają pełnej korekcji błędów. Nie nadają się do uruchamiania „dużych”, idealnych algorytmów znanych z publikacji naukowych, ale umożliwiają praktyczne eksperymenty z obliczeniami kwantowymi w skali małych i średnich problemów.
Kluczowa różnica w stosunku do wielu wcześniejszych przełomów technologicznych polega na tym, że do komputerów kwantowych dostęp uzyskuje się zdalnie, przez chmurę. IBM, Amazon (Braket), Microsoft (Azure Quantum), Google i kilku mniejszych dostawców oferuje już dziś API, które umożliwia wysyłanie obwodów kwantowych do wykonania na fizycznym sprzęcie albo wysokiej jakości symulatorach. Developer nie musi być naukowcem prowadzącym eksperymenty laboratoryjne – wystarczy konto w chmurze i znajomość odpowiedniego SDK.
To przenosi „erę kubitów” z poziomu laboratoriów na poziom architektury systemów. Nawet jeśli algorytmy kwantowe nie dają jeszcze wyraźnego przyspieszenia dla Twojego scenariusza, już teraz pojawia się pytanie: jak zaprojektować kod i warstwę integracji tak, aby nie zamknąć sobie drogi do skorzystania z tych akceleratorów za kilka lat, kiedy sprzęt dojrzeje.
Dziedziny, w których testuje się algorytmy kwantowe
Choć pełne „kwantowe przyspieszenie” (tzw. quantum advantage) jest wciąż przedmiotem badań, są konkretne obszary, gdzie firmy już eksperymentują:
Optymalizacja kombinatoryczna – planowanie tras, harmonogramowanie, alokacja zasobów, portfele inwestycyjne. Wykorzystuje się warianty QAOA (Quantum Approximate Optimization Algorithm) czy D-Wave Annealing.
Chemia kwantowa i materiały – symulacje cząsteczek, reakcje chemiczne, projektowanie nowych materiałów i leków. Tu korzysta się z algorytmów typu VQE (Variational Quantum Eigensolver).
Uczenie maszynowe – kwantowe kernele, kwantowe sieci neuronowe, przyspieszanie zadań klasyfikacji i klasteryzacji. Większość to na razie prototypy, ale integrują się z istniejącymi pipeline’ami ML.
Problemy liniowo-algebraiczne – rozwiązywanie układów równań liniowych, dekompozycje macierzowe. Często w fazie proof-of-concept z uwagi na ograniczoną skalę dostępnych maszyn.
Wspólny mianownik: są to zadania obliczeniowo ciężkie, często złożone wykładniczo lub z dużym kosztem energetycznym, gdzie każde przyspieszenie o rząd wielkości ma znaczenie biznesowe. Nawet jeśli obecne urządzenia NISQ nie osiągają jeszcze takiego przyspieszenia, sam fakt, że dostęp do nich jest realizowany przez API, pozwala wbudować „gniazda” na przyszłe akceleratory w aktualnej architekturze.
Co znaczy „przygotować kod na erę kubitów”
Przygotowanie kodu nie polega na przepisywaniu całej aplikacji na Q#, Qiskit czy Cirq. Kluczem jest rozdzielenie logiki na część klasyczną i potencjalnie kwantową oraz zaprojektowanie interfejsów między nimi tak, by:
algorytmicznie wyodrębnić podproblemy, które mogą być rozwiązane przez kwantowy „koprocesor”,
zdefiniować klarowne kontrakty wejście/wyjście takiego modułu (dane wejściowe, format wyników, tolerancja błędu),
umożliwić wymianę implementacji: dziś klasyczny solver, jutro hybrydowy albo czysto kwantowy.
Chodzi więc o architekturę i modularność, a nie o masową migrację kodu. Aplikacja, która posiada dobrze wydzieloną warstwę „ciężkiej” optymalizacji, ML lub symulacji, będzie dużo łatwiej korzystać z kwantowych API niż monolit z gęsto zaszytą logiką algorytmiczną.
Kto zyska pierwszy, a kto może poczekać
Korzyści z wczesnego wejścia w obliczenia kwantowe są bardzo nierównomiernie rozłożone. Decyzja, czy inwestować już teraz, zależy od profilu systemu i biznesu.
Realni wcześni beneficjenci to m.in.:
firmy logistyczne i operatorskie, których zysk silnie zależy od optymalizacji tras, harmonogramów, alokacji floty,
farmacja, chemia i materiały – koszt symulacji i eksperymentów jest wysoki, a nawet niewielkie skrócenie czasu R&D ma ogromną wartość,
duże zespoły R&D, które chcą zbudować kompetencje wcześniej niż konkurencja.
Kto może spokojnie poczekać? Aplikacje CRUD, typowe systemy biznesowe, większość serwisów webowych, moduły raportowe. Jeżeli profil obciążenia to głównie operacje I/O, przetwarzanie transakcyjne, proste agregacje, to kubity nie przyniosą przewagi w najbliższym czasie. Mimo to warto projektować system tak, aby algorytmicznie ciężkie fragmenty (np. rekomendacje, personalizacja, scoring) były wydzielone– wtedy przejście na hybrydę będzie kwestią podmiany modułu, a nie przebudowy wszystkiego od zera.
Podstawy obliczeń kwantowych z perspektywy programisty
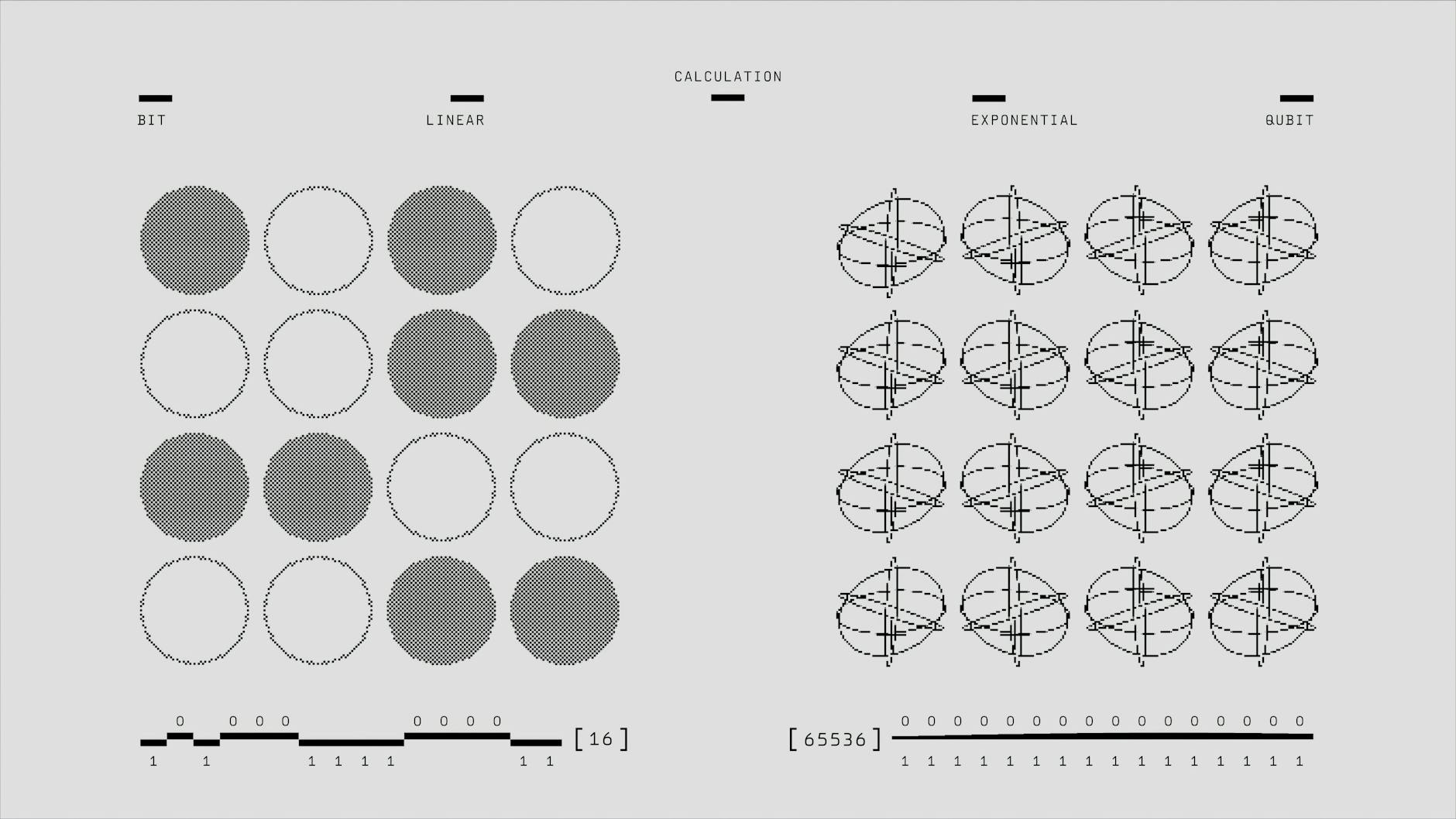
Kubyty, superpozycja i splątanie „po inżyniersku”
Kubit można traktować jako uogólnienie bitu. Zamiast przyjmować wartość 0 lub 1, kubit jest opisany stanem, który można zapisać jako kombinację obu: a|0> + b|1>, gdzie a i b są amplitudami. W praktyce przekłada się to na fakt, że obwód kwantowy przetwarza równocześnie wiele możliwych konfiguracji, a nie tylko jedną, jak w klasycznym kodzie.
Superpozycja oznacza, że kubit jest w „mieszance” 0 i 1, dopóki nie zostanie zmierzony. Po pomiarze stan „zapada się” do jednej z wartości klasycznych z pewnym prawdopodobieństwem. Dla programisty ważne jest, że obwód kwantowy nie zwraca deterministycznej odpowiedzi po jednym uruchomieniu – trzeba liczyć wiele „shots” (wykonań), aby oszacować rozkład wyników.
Splątanie to korelacja między kubitami, której nie da się wytłumaczyć klasyczną statystyką. Z punktu widzenia kodu, splątane kubity zachowują się jak dane współdzielące jeden wspólny stan, który reaguje na operacje wykonywane na którejkolwiek części. Dzięki temu możliwe są operacje globalne na przestrzeni stanów, których nie da się efektywnie zasymulować klasycznie.
Obwód kwantowy jako „funkcja”
Najpopularniejszy model programowania to model obwodowy. Dla developera można go postrzegać jako funkcję, która:
tworzy rejestr kubitów (odpowiednik parametrów wejściowych / stanu początkowego),
aplikuje sekwencję bramek (operacji kwantowych),
przeprowadza pomiar (konwersja do bitów klasycznych i zwrot wyniku).
Bramki kwantowe (X, H, CNOT, RZ itd.) są odpowiednikiem instrukcji procesora albo operacji na wektorze stanu. Z punktu widzenia kodu budujesz obiekt typu circuit, dodajesz do niego bramki w określonej kolejności, a następnie wysyłasz ten obiekt do wykonania na symulatorze lub fizycznym urządzeniu.
Typowy workflow w Qiskit lub Cirq wygląda podobnie do tworzenia grafu obliczeniowego w frameworkach ML: najpierw deklaracja struktury obliczeń, potem wykonanie w wybranym backendzie (simulator, hardware).
Choć model obwodowy jest najczęściej spotykany w materiałach edukacyjnych, z perspektywy kodu warto znać trzy główne podejścia:
Model obwodowy – sekwencja bramek na kubitach, pełna kontrola nad obwodem. Wykorzystywany przez IBM, Google, Azure Quantum i większość narzędzi open-source (Qiskit, Cirq, Q#, Braket SDK).
Model adiabatyczny / annealing – programowanie polega na zakodowaniu problemu optymalizacyjnego w postaci funkcji energii (np. QUBO – Quadratic Unconstrained Binary Optimization), a urządzenie „szuka” minimum tej funkcji. D-Wave i podobne systemy często korzystają z tego podejścia. Kod przypomina integrację z solverem optymalizacyjnym, nie z obwodem logicznym.
Modele hybrydowe VQA (Variational Quantum Algorithms) – część parametrów jest optymalizowana klasycznie (gradienty, optymalizatory), a obwód kwantowy jest uruchamiany wielokrotnie jako „czarna skrzynka” zwracająca wartość funkcji celu.
Dobór modelu wpływa na strukturę kodu: w obwodowym budujesz eksplicytny obwód, w annealingu tworzysz macierz kosztu, a w VQA piszesz pętlę optymalizacji, która woła backend kwantowy jak funkcję kosztu.
Ograniczenia praktyczne: szum, liczba kubitów, głębokość obwodu
Dzisiejsze urządzenia NISQ są dalekie od teorii. Trzy aspekty szczególnie wpływają na sposób pisania kodu:
Liczba kubitów fizycznych vs logicznych – w tekstach naukowych często zakłada się idealne kubity logiczne. W rzeczywistości wiele kubitów fizycznych trzeba przeznaczyć na korekcję błędów i redundancję, co ogranicza realną skalę algorytmu.
Szum i błędy – bramki i kubity mają skończone czasy koherencji, a ich operacje są niedoskonałe. Im dłuższy (głębszy) obwód, tym większe prawdopodobieństwo, że wynik będzie zakłócony.
Głębokość obwodu – liczba warstw bramek wykonywanych sekwencyjnie. W praktyce trzeba ograniczać złożoność obwodu, reparameterzywać algorytm i stosować techniki optymalizacji obwodów.
Konsekwencja dla programisty: „papierowy” algorytm trzeba przystosować do sprzętu. Często oznacza to uproszczenia, przybliżenia, cięcie problemu na mniejsze instancje, które mieszczą się w dostępnych kubitach i dopuszczalnej głębokości obwodu.
Minimum, które powinien rozumieć backendowiec
Backendowiec, który ma projektować architekturę z myślą o kwantowym akceleratorze, nie musi umieć wyprowadzać równań Schrödingera. Powinien natomiast rozumieć kilka kluczowych faktów:
obwód kwantowy to czarna skrzynka o określonych parametrach wejściowych i statystycznym wyniku wyjściowym,
wywołanie backendu kwantowego może być wolne (sekundy lub minuty) i podatne na błędy,
każde zapytanie zwraca rozkład wyników, więc część logiki statystycznej żyje w warstwie klasycznej,
integracja będzie przebiegała jak z usługą zewnętrzną (REST, gRPC, SDK), a nie jak z lokalną biblioteką kryptograficzną.
Resztę – optymalizację bramek, mapowanie na fizyczne kubity, redukcję szumu – można i trzeba zostawić bibliotekom, kompilatorom i narzędziom dostawcy. Rola backendowca to dobrze wydzielić moduły, zapanować nad przepływem danych oraz zadbać o odporność na błędy i czas odpowiedzi.
Źródło: Pexels | Autor: Google DeepMind
Kiedy algorytm kwantowy ma sens: identyfikacja kandydatów w istniejącym kodzie
Klasy problemów sprzyjających podejściu kwantowemu
Nie wszystkie zadania nadają się do przyspieszenia kwantowego. Poszukiwanie kandydatów w istniejącej bazie kodu warto oprzeć na klasach problemów, gdzie już dziś trwają intensywne badania:
Wyszukiwanie i eksploracja przestrzeni rozwiązań – duże zbiory danych, przestrzenie stanów, zadania typu „znajdź element spełniający warunek” (Grover i warianty).
Optymalizacja kombinatoryczna – problemy NP-trudne, takie jak VRP (Vehicle Routing Problem), TSP (Traveling Salesman Problem), przydział zasobów, harmonogramowanie z constraintami.
Symulacje fizyczne i chemiczne – tam, gdzie klasyczne symulacje skaluje się bardzo słabo wraz z liczbą cząstek/stopni swobody.
Problemy liniowo-algebraiczne – duże układy równań, systemy rzadkie, metody iteracyjne, zadania podobne do tych w ML (dekompozycje, spektrum macierzy).
Jeżeli w kodzie pojawiają się własne implementacje lub integracje z solverami MILP, SAT, MIP, dużymi solverami optymalizacyjnymi czy biblioteki numeryczne, jest spora szansa, że to odpowiednie miejsce na przyszły moduł kwantowy.
Kryteria wyboru: czy problem jest „kwantowo-obiecujący”
Aby nie popaść w modę bez uzasadnienia, można zdefiniować prosty zestaw kryteriów. Jeśli dane zadanie spełnia większość z nich, jest kandydatem do eksperymentów:
Praktyczna checklista dla legacy codebase
Przy analizie istniejącego systemu pomocne jest przejście po kilku prostych pytaniach. Można je traktować jak filtr, przez który przechodzą moduły aplikacji:
Czy jest tu „twarde” ograniczenie wydajności? – własne implementacje heurystyk, algorytmy działające minutami lub godzinami, kolejki zadań optymalizacyjnych.
Czy problem rośnie wykładniczo lub kombinatorycznie? – każdorazowe dodanie nowego wymiaru (np. produktu, zasobu, regionu) powoduje gwałtowny wzrost czasu liczenia.
Czy kod korzysta z zewnętrznych solverów lub bibliotek numerycznych? – integracje z CPLEX, Gurobi, OR-Tools, dużymi solverami SAT/SMT, bibliotekami algebry liniowej.
Czy można zaakceptować wynik przybliżony? – obszary typu rekomendacje, pricing dynamiczny, optymalizacja kampanii, gdzie „wystarczająco dobre” bywa lepsze niż „optymalne po 3 godzinach”.
Czy dane są w miarę uporządkowane i łatwe do wektorowego przetworzenia? – im więcej struktury, tym łatwiej odwzorować problem na postać akceptowaną przez algorytmy kwantowe (macierze, grafy, QUBO).
Jeśli moduł spełnia trzy–cztery z powyższych punktów, kandydat jest sensowny. W praktyce taką analizę warto robić przy większych refactoringach: obok „czy podzielić monolit”, dopisać „czy da się wyodrębnić potencjalny moduł kwantowy”.
Granice sensu: kiedy odpuścić kwanty
Są też obszary, gdzie inwestowanie w prototyp kwantowy nie ma dziś większego sensu:
proste CRUD-y, raporty przekładające dane 1:1,
małe problemy, które rozwiązuje pojedyncza maszyna w milisekundy,
taski silnie I/O-bound (ładowanie plików, integracje z API), gdzie wąskim gardłem nie jest CPU, tylko sieć lub dysk,
algorytmy silnie gałęziujące się, zależne od wielu warunków logicznych i stanów sesji, które trudno „spłaszczyć” do modelu matematycznego.
Jeśli logika zawiera zdanie „i tak większość czasu spędzamy na czekaniu na zewnętrzny serwis”, to kwantowy akcelerator niewiele zmieni. W takich miejscach lepiej skupić się na klasycznej optymalizacji, cache’owaniu lub zmianie kontraktu z zewnętrznym systemem.
Refaktoryzacja pod kątem przyszłego backendu kwantowego
Jeśli w kodzie odnajdzie się kandydat, kolejnym krokiem jest techniczny „lifting”. Chodzi o to, aby wyizolować ciężki fragment tak, by w przyszłości można było podmienić backend na kwantowy bez ruszania reszty systemu. Typowe działania to:
wydzielenie modułu optymalizacyjnego / wyszukującego z logiki biznesowej,
zdefiniowanie kontraktów wejście–wyjście tak, by były niezależne od sposobu liczenia (np. JSON opisujący problem QUBO, zamiast struktury powiązanej z konkretnym solverem),
rezygnacja z globalnego stanu na rzecz jawnych parametrów funkcji i czystych zależności,
dopisanie testów regresyjnych mierzących jakość rozwiązania, a nie tylko konkretny wynik (np. „funkcja celu <= X”, „naruszenie constraintów <= Y”).
Taka refaktoryzacja przydaje się od razu, nawet bez kwantów: ułatwia wymianę solverów i eksperymenty z różnymi heurystykami, a później – dołożenie wersji kwantowej jako jednej z opcji.
Modele hybrydowe: współpraca klasycznych systemów z kwantowymi akceleratorami
Architektoniczny wzorzec „koprocesora kwantowego”
Najprostszy sposób myślenia o kwantowym backendzie to traktowanie go jak koprocesor lub zewnętrzny serwis obliczeniowy. Klasyczny system:
przygotowuje dane wejściowe i redukuje je do postaci obsługiwanej przez algorytm kwantowy (np. QUBO, macierz, graf),
wywołuje zadanie na urządzeniu kwantowym przez API dostawcy (HTTP, gRPC, SDK),
odbiera statystyczny wynik, dokonuje postprocessingu i walidacji,
w razie potrzeby wykonuje fallback do klasycznego solvera.
Taki wzorzec jest najbardziej naturalny w systemach, które i tak już dziś wysyłają ciężkie zadania do zewnętrznych klastrów, chmur lub specjalizowanych usług (np. renderowanie, uczenie modeli ML).
Asynchroniczność i zarządzanie kolejką zadań
Czasy odpowiedzi urządzeń kwantowych są na razie dalekie od „microservice latency”. Trzeba zakładać, że:
jedno zadanie może trwać sekundy lub dłużej,
sloty na urządzeniach są współdzielone między wieloma klientami,
część zadań może zostać odrzucona lub wymagać ponownego uruchomienia.
Dlatego bardziej naturalny jest model asynchroniczny: publikacja zadań do kolejki (Kafka, RabbitMQ, SQS), worker kwantowy odpowiedzialny za komunikację z dostawcą oraz warstwa orkiestracji. Interfejs do reszty systemu przypomina raczej system batchowy niż „zwykły” REST.
Pętla sprzężenia zwrotnego w algorytmach wariacyjnych
W algorytmach typu VQE czy QAOA kluczowa jest pętla:
klasyczny optymalizator wybiera parametry obwodu,
urządzenie kwantowe wykonuje obwód i zwraca wartość funkcji celu,
klasyczny komponent aktualizuje parametry i ponawia wywołanie.
Z punktu widzenia kodu przypomina to uczenie modelu ML, tylko „inference” odbywa się na urządzeniu kwantowym. Przy projektowaniu takiej pętli trzeba wziąć pod uwagę:
koszt pojedynczego wywołania – im droższe, tym mocniej opłaca się inteligentny wybór kolejnych punktów (Bayesian optimization zamiast prostego gradientu),
tolerancję na brak deterministyczności – funkcja celu ma szum pomiarowy, więc optymalizator musi radzić sobie z niepewnością,
możliwość równoległego „strzelania” parametrami – wysyłanie kilku konfiguracji naraz, jeśli backend na to pozwala, aby zredukować wpływ latency.
Fallback i degradacja jakości usług
W realnym systemie nie można zakładać stuprocentowej dostępności ani stabilności jakości wyników z urządzenia kwantowego. Potrzebne są mechanizmy:
automatycznego przełączenia na klasyczny solver, jeśli czas lub liczba nieudanych prób przekroczy próg,
porównywania jakości – okresowe uruchamianie obu wersji (klasycznej i kwantowej) na mniejszych instancjach, aby monitorować, czy kwantowy pipeline nadal daje przewagę,
logowania cech problemu – rozmiar instancji, struktura, ustawienia parametrów; pozwala to później zbudować heurystykę „kiedy opłaca się wysłać problem na kwanty”.
W praktyce sensowne jest przyjęcie założenia: „system nigdy nie zawodzi z powodu kwantów” – awaria akceleratora nie może być przyczyną niedostępności krytycznej funkcji biznesowej.
Źródło: Pexels | Autor: Google DeepMind
Języki, frameworki i narzędzia: jak programuje się obliczenia kwantowe
Warstwa SDK: Qiskit, Cirq, Braket i spółka
Podstawowy poziom to biblioteki umożliwiające budowę obwodów i integrację z backendami. Dla programistów Pythona sytuacja jest prosta – większość ekosystemu jest właśnie tam:
Qiskit (IBM) – rozbudowany ekosystem z modułami do symulacji, optymalizacji, chemii kwantowej i integracji z backendami IBM Quantum.
Cirq (Google) – skupia się na modelu obwodowym i integracji z hardware’em wspieranym przez Google, dobrze pasuje do środowiska TensorFlow/JAX.
Amazon Braket SDK – ujednolicony interfejs do kilku dostawców (IonQ, Rigetti, OQC, D-Wave), zintegrowany z AWS.
inne: PennyLane (silne VQA i ML), Strawberry Fields (fotoniczne), tket, pyQuil i kolejne niszowe projekty.
Od strony kodu buduje się obiekt reprezentujący obwód, przypisuje go do „urządzenia” (symulator lub fizyczny backend) i wykonuje. Modele obliczeniowe są do siebie podobne, więc migracja między frameworkami jest w większości przypadków możliwa przy umiarkowanym wysiłku.
Języki wysokiego poziomu: Q#, QIR i specyficzne DSL-e
Drugą warstwę stanowią języki bardziej „samodzielne”, z własnymi kompilatorami:
Q# (Microsoft) – język zaprojektowany specjalnie dla obliczeń kwantowych, integrujący się z .NET i Azure Quantum. Pozwala oddzielić logikę klasyczną (C#, F#) od kwantowej (Q#).
QIR – pośrednia reprezentacja obwodów oparta na LLVM, ważna, jeśli zależy na przenośności między różnymi backendami hardware’owymi.
DSL-e domenowe – np. języki opisujące problemy QUBO, często w formacie zbliżonym do plików konfiguracyjnych solverów.
Tego typu narzędzia są istotne tam, gdzie planuje się większy projekt kwantowy: dają lepszą kontrolę nad kompilacją, optymalizacją obwodów i integracją z pipeline’ami CI/CD.
Symulatory i emulatory: główne środowisko developerskie
Na etapie tworzenia i testowania kodu praktycznie wszystko dzieje się na symulatorach. Typowo dostępne są:
symulator stanu pełnego – najbardziej dokładny, ale rosnący wykładniczo z liczbą kubitów,
symulatory szumowe – modele z zadanym profilem błędów, przydatne, jeśli chce się zbliżyć do realnego hardware’u,
symulatory przybliżone – różne dekompozycje, trunkacje i techniki redukcji wymiaru, dające skalowalność kosztem dokładności.
W praktyce sensowne jest podejście warstwowe: logika i kontrakty są testowane na czystym symulatorze, a dopiero później sprawdzane na szumowym modelu urządzenia docelowego, aby ocenić realną wykonalność obwodu.
Integracja z narzędziami klasycznymi: ML, DevOps, obserwowalność
Nowoczesne projekty kwantowe rzadko są „samodzielne”. Kod kwantowy jest osadzony w znanych środowiskach:
ML/AI – PennyLane, TensorFlow Quantum czy TorchQuantum pozwalają włączać „warstwy” kwantowe do modeli klasycznych; dla developera wygląda to podobnie jak kolejne typy layerów.
DevOps – obwody, konfiguracje backendów i parametry optymalizacji trzyma się w repozytoriach, buduje pipeline’y CI z testami na symulatorach i prostymi sanity-checkami na fizycznym sprzęcie.
Monitoring – zbieranie metryk: czas oczekiwania na slot, liczba nieudanych jobów, statystyki błędów, porównanie jakości rozwiązań z wersją klasyczną.
Z punktu widzenia inżyniera infrastruktury backend kwantowy nie jest niczym magicznym – to kolejny typ zasobu, który trzeba opakować w standaryzowane interfejsy i monitorować jak każdy inny.
Projektowanie pod ograniczenia NISQ: szum, liczba kubitów i głębokość obwodu
Redukcja wymiaru problemu przed „wejściem na kwanty”
Na obecnym sprzęcie kluczowa jest agresywna redukcja problemu po stronie klasycznej. Typowe techniki to:
preprocessing danych – filtrowanie mało istotnych elementów, grupowanie podobnych jednostek (klienci, produkty, zasoby),
dekompozycja problemu – dzielenie go na mniejsze instancje, które mieszczą się w dostępnym budżecie kubitów; późniejsze scalenie rozwiązań może przebiegać heurystycznie,
relaksacja constraintów – przeniesienie części ograniczeń do fazy postprocessingu (np. karanie za naruszenia zamiast twardego ich wymuszania w QUBO).
W codziennym kodzie oznacza to osobne moduły do przygotowania instancji „pod hardware” oraz do późniejszego złożenia wyniku w struktury używane przez resztę aplikacji.
Ograniczanie głębokości obwodu: kompozycja i optymalizacja
Głębokość obwodu jest jednym z najważniejszych parametrów: im większa, tym silniejszy wpływ szumu. Technicznie można na to zareagować na kilka sposobów:
wykorzystanie kompilatorów – Qiskit, Cirq i inne narzędzia oferują optymalizację obwodów: redukcję liczby bramek, zamianę na natywne bramki hardware’u, reordering kubitów.
projektowanie „płytkich” ansatzów w algorytmach wariacyjnych – zamiast bardzo wyrafinowanych struktur, lepiej zacząć od kilku warstw dobrze wybranych bramek.
Strategie radzenia sobie z szumem i błędami
Szum i błędy bramek są nieuniknione, więc większy sens ma zarządzanie nimi niż czekanie na „idealny” hardware. Używa się tu kilku praktycznych technik, często łączonych:
error mitigation – korekta statystyczna wyników bez pełnego kodowania kwantowego; przykładowo: extrapolacja do zera szumu (uruchamianie obwodu z różnym poziomem „rozciągnięcia” bramek i estymacja wartości w limicie idealnym),
measurement error mitigation – kalibracja błędów pomiaru; przed właściwymi zadaniami wykonuje się krótkie obwody referencyjne, aby zbudować macierz zamiany stanów (np. jak często |0⟩ jest odczytywane jako |1⟩),
symetrie i postselekcja – jeśli problem ma znaną symetrię (np. liczba cząstek w chemii), pomiary łamiące tę symetrię można odrzucać, podnosząc jakość średniej,
redundantne kodowanie wyniku – czasem opłaca się zakodować tę samą wielkość obserwowalną kilkoma różnymi obwodami i porównać ich rozkłady.
Dla programisty oznacza to osobne moduły „kalibracji” i „korekcji wyników” oraz testy A/B: ten sam obwód uruchamiany z i bez mitigation, aby zobaczyć, jak zmieniają się odchylenia od symulatora szumowego.
Topologia sprzętu i mapowanie kubitów
Fizyczne urządzenia mają ograniczoną łączność kubitów: nie każdy kubit może bezpośrednio oddziaływać z każdym. Powoduje to potrzebę wstawiania dodatkowych bramek SWAP, które zwiększają głębokość i wrażliwość na szum. Kiedy kompilator „puchnie” od SWAP-ów, wydajność algorytmu gwałtownie spada.
Praktyczne podejścia:
świadome mapowanie rejestrów – ręczne przypisywanie logicznych kubitów do fizycznych tak, aby najbardziej „komunikujące się” pary były blisko w topologii urządzenia,
layout-aware design – projektowanie obwodów z uwzględnieniem znanej grafowej struktury sprzętu (np. grid, heavy-hex); niektóre ansatze mają warianty zoptymalizowane pod określoną topologię,
porównywanie backendów – ten sam obwód może zachowywać się lepiej na innym urządzeniu tylko dlatego, że ma bardziej sprzyjającą topologię; przy korzystaniu z chmury warto testować.
W kodzie sprawdza się to jako osobny krok w pipeline’ie: „przed kompilacją” obwodu wybierany jest backend, a następnie używany jest kompilator specyficzny dla danego urządzenia, który potrafi wykorzystywać jego geometrię.
Budżet zasobów jako „constraint” w projektowaniu algorytmu
W klasycznym świecie optymalizuje się głównie czas i pamięć. W NISQ dochodzą parametry kwantowe: liczba kubitów, głębokość obwodu, liczba powtórzeń (shots), czas kolejki do urządzenia. Projektując algorytm, można jawnie traktować je jako ograniczenia:
„maksymalnie N kubitów logicznych” – reszta musi zostać zredukowana lub przesunięta do fazy klasycznej,
„maksymalna głębokość D” – obwód powyżej tej wartości uznajemy za niewykonalny na wybranym sprzęcie,
„czas wykonania zadania <= T” – liczba shotów i złożoność ansatzu są z góry limitowane.
Przekłada się to na mało efektowne, ale skuteczne decyzje: mniej rozbudowane ansatze, prostsze mapowania problemu na obwód, agresywniejszą redukcję instancji. Często to właśnie ta dyscyplina sprawia, że prototyp staje się realnym komponentem w systemie.
Testowanie poprawności w warunkach szumowych
Same testy jednostkowe uruchamiane na idealnym symulatorze są niewystarczające. Ten sam obwód w obecności szumu może zachowywać się diametralnie inaczej. Proces testowania rozszerza się więc o:
testy „kontraktowe” na szumowych symulatorach – sprawdzanie, czy rozkład wyników pozostaje w określonym przedziale (np. średnia wartości funkcji celu mieści się w zadanym oknie),
regresję względną – porównywanie nowych wersji obwodów i procedur mitigation z poprzednimi, zamiast z absolutnie idealnym wynikiem,
testy na małych instancjach – takie, które można dokładnie policzyć klasycznie, co pozwala oszacować skalę błędów kwantowych.
Dobrym wzorcem jest łączenie testów offline (w CI, tylko symulatory) z okresowymi kampaniami testowymi na fizycznym sprzęcie, np. raz na sprint lub przed większym wydaniem.
Refaktoryzacja istniejącego kodu pod kątem kwantowych akceleratorów
Kiedy w projekcie pojawia się pomysł użycia komputera kwantowego, najczęściej istnieją już duże bazy kodu klasycznego. Zamiast przepisywać całość, sens ma stopniowa refaktoryzacja w kierunku lepszej separacji warstw:
wydzielenie „jądra obliczeniowego” – izolacja części odpowiadającej za trudne obliczenia (np. solver optymalizacyjny, moduł symulacji) w postaci dobrze zdefiniowanego interfejsu,
wprowadzenie abstrakcji „solvera” – interfejsu, który może mieć implementację klasyczną i kwantową; wybór implementacji następuje na podstawie konfiguracji lub heurystyk,
oddzielenie warstwy modelu od warstwy algorytmicznej – modele danych (np. harmonogramy, grafy, portfele) nie powinny znać szczegółów o tym, jak są rozwiązywane.
W praktyce przypomina to przygotowanie istniejącego systemu na GPU: tam, gdzie wcześniej wywoływana była funkcja licząca „na CPU”, pojawia się abstrakcja pozwalająca przełączyć się na inny typ akceleratora, w tym przypadku kwantowy.
Projektowanie interfejsów API dla komponentów kwantowych
Aby komponent kwantowy nie „rozlał się” po całej bazie kodu, dobrze zdefiniowany kontrakt API jest kluczowy. Zamiast zwracać surowe bitstringi, warto projektować bardziej semantyczne struktury:
dla problemów optymalizacyjnych – najlepsze znalezione rozwiązanie, kilka rozwiązań alternatywnych oraz metadane o jakości (wartość funkcji celu, rozrzut, liczba pomiarów),
dla problemów probabilistycznych – znormalizowane rozkłady, z których można próbować dalej w kodzie klasycznym,
dla zastosowań w ML – tensory kompatybilne z frameworkami typu PyTorch / TensorFlow.
Dodatkowo interfejs powinien przenosić informacje operacyjne: identyfikator joba, statystyki hardware’u, wersję kompilatora. To ułatwia późniejsze debugowanie, gdy wyniki różnią się między wersjami backendu.
Wzorce architektoniczne dla „kwantowych usług”
W większych organizacjach komponenty kwantowe zaczynają funkcjonować jako osobne usługi, które obsługują wielu konsumentów. Sprawdza się kilka prostych wzorców:
„quantum as a service” w obrębie firmy – centralny zespół utrzymuje usługę udostępniającą API do wybranych solverów kwantowych, inne zespoły konsumują wyniki jak zewnętrzną usługę optymalizacyjną,
kolejki i priorytety – zadania kwantowe, z natury partiowe i drogie, przechodzą przez dedykowaną kolejkę z politykami priorytetów (np. eksperymenty vs. krytyczne batch’e nocne),
cache wyników – dla powtarzających się instancji problemu (lub ich podobnych wersji) opłaca się cache’owanie rozwiązań i używanie kwantowego backendu tylko wtedy, gdy instancja znacząco się zmienia.
Z technicznego punktu widzenia komponent kwantowy przypomina serwis ML z kosztownym inference’em: ma kolejki, przydział zasobów, cache, monitoring SLA.
Zarządzanie wersjami obwodów i eksperymentami
W miarę rozwoju projektu liczba obwodów, parametrów i konfiguracji backendu szybko rośnie. Bez dyscypliny w wersjonowaniu trudno potem odtworzyć, dlaczego w danym momencie wyniki wyglądały lepiej lub gorzej. Pomaga podejście znane z MLOps:
repozytorium obwodów – kod obwodów traktowany jak kod aplikacji: pull requesty, code review, tagowanie wersji,
tracking eksperymentów – narzędzia pokroju MLflow lub własne rozwiązania, w których zapisuje się: commit kodu, konfigurację backendu, date, metryki jakości,
feature flags dla ścieżek kwantowych – umożliwiające stopniowe włączanie lub wyłączanie nowej wersji obwodu dla części ruchu.
W wielu przypadkach to właśnie historia eksperymentów pozwala stwierdzić, że przewaga kwantowej wersji jest stabilna, a nie przypadkowa.
Bezpieczeństwo i compliance w kontekście chmurowych backendów kwantowych
Większość dostępu do sprzętu kwantowego odbywa się przez chmurę, co rodzi typowe pytania o bezpieczeństwo i zgodność z regulacjami. Technicznie nie różni się to mocno od korzystania z innych usług obliczeniowych, ale warto uwzględnić kilka aspektów:
klasyfikacja danych wejściowych – czy instancje problemu zawierają dane wrażliwe? Jeśli tak, trzeba je anonimizować lub agregować przed wysłaniem do chmury,
lokalizacja centrów danych – część regulacji (np. w finansach czy sektorze publicznym) wymaga przetwarzania w określonych regionach; dotyczy to również backendów kwantowych,
audyt i logi – kto i kiedy wysyłał zadania, z jakim payloadem i do jakiego dostawcy; te dane przydają się nie tylko w razie incydentów, ale też przy optymalizacji kosztów.
Od strony API pomaga prosty wzorzec: osobna warstwa „gateway” w infrastrukturze, która kontroluje, co jest wysyłane na zewnątrz, maskuje wrażliwe identyfikatory i dodaje standardowe logowanie.
Szacowanie i kontrola kosztów obliczeń kwantowych
Dostęp do realnego hardware’u bywa rozliczany per czas wykonania, liczba shotów lub suma wykonanych bramek. Jeśli pozostawić to bez kontroli, łatwo o nieprzyjemne zaskoczenia na fakturze. W praktyce stosuje się kilka prostych zasad:
limity budżetu na środowisko – rozdział na środowiska dev/test/prod z różnymi limitami, przy czym środowisko dev zwykle ma dostęp tylko do symulatorów,
domyślne użycie symulatorów – przełączenie na fizyczny backend wymaga świadomej decyzji (np. flagi konfiguracyjnej lub innego endpointu),
raportowanie kosztów – metryki liczby jobów, shotów i czasu wykonania zgrupowane po zespołach i projektach, udostępniane jak typowe raporty kosztów chmurowych.
Pomaga również wczesne ustalenie zasad: które typy zadań mogą korzystać z prawdziwego urządzenia, a które muszą pozostać na symulacji, dopóki nie udowodni się realnej przewagi.
Kompetencje zespołu i podział ról
Przygotowanie kodu na erę kubitów nie oznacza, że każdy developer musi stać się fizykiem kwantowym. Bardziej efektywny bywa prosty podział ról:
inżynierowie aplikacji – skupiają się na logice biznesowej, integracji, API, bezpieczeństwie i obsłudze błędów,
specjaliści od algorytmów kwantowych / naukowcy – projektują ansatze, wybierają metody optymalizacji, analizują wpływ szumu,
inżynierowie infrastruktury – dbają o konfigurację backendów, kolejki zadań, monitoring i koszty.
Na styku tych ról powstają stabilne interfejsy: kontrakty danych, specyfikacje usług, standardy logowania. Dzięki temu zmiany w algorytmach kwantowych nie łamią reszty systemu, a developera aplikacyjnego interesuje głównie to, że istnieje kolejny typ „solvera”, który można wywołać z poziomu jego kodu.
Najczęściej zadawane pytania (FAQ)
Co to są komputery kwantowe NISQ i czym różnią się od „docelowych” maszyn kwantowych?
Komputery NISQ (Noisy Intermediate-Scale Quantum) to obecna generacja urządzeń kwantowych: mają ograniczoną liczbę kubitów, są podatne na szum i nie posiadają pełnej korekcji błędów. Można na nich uruchamiać tylko relatywnie małe obwody, a wyniki mają charakter probabilistyczny i obarczony szumem.
„Docelowe” komputery kwantowe (z pełną korekcją błędów) będą w stanie wykonywać duże, złożone algorytmy znane z publikacji naukowych, np. do łamania kryptografii czy precyzyjnych symulacji chemicznych na dużą skalę. Na razie takich maszyn nie ma w praktycznym użyciu, dlatego pracuje się głównie z urządzeniami NISQ oraz ich symulatorami w chmurze.
Jak jako programista mogę zacząć korzystać z komputerów kwantowych w praktyce?
Dostęp do komputerów kwantowych odbywa się przez chmurę, za pomocą API oferowanych m.in. przez IBM, Amazon Braket, Microsoft Azure Quantum czy Google. Potrzebne jest konto u dostawcy, wybór odpowiedniego SDK (np. Qiskit, Cirq, Q#, Braket SDK) oraz podstawowa znajomość modelu obwodowego.
W praktyce budujesz obwód kwantowy jako strukturę danych w kodzie, wysyłasz go do wybranego backendu (symulator lub fizyczne urządzenie) i odbierasz wyniki pomiarów. Dobrze sprawdza się podejście iteracyjne: najpierw prototyp na symulatorze, a potem testy na prawdziwym sprzęcie w chmurze.
Co znaczy „przygotować kod na erę kubitów” w istniejącej aplikacji?
Chodzi o takie zaprojektowanie architektury, żeby potencjalne „ciężkie” obliczenia można było w przyszłości przenieść do kwantowego koprocesora bez przepisywania całego systemu. Zamiast monolitu z gęsto zaszytą logiką algorytmiczną warto wydzielić moduły odpowiedzialne za optymalizację, zaawansowane ML czy symulacje.
Od strony praktycznej przydaje się:
wyodrębnienie podproblemów, które mogą być rozwiązane przez kwantowy moduł (np. solver optymalizacyjny),
zdefiniowanie jasnych kontraktów wejście/wyjście (format danych, dopuszczalny błąd, czas odpowiedzi),
warstwa abstrakcji, która dziś wykorzystuje klasyczne algorytmy, a w przyszłości może pod spodem wywoływać API kwantowe.
Jakie typy problemów najbardziej skorzystają z komputerów kwantowych?
Najwięcej uwagi przyciągają problemy obliczeniowo bardzo kosztowne, często złożone wykładniczo lub wymagające dużego zużycia energii. Do najczęściej wymienianych obszarów należą optymalizacja kombinatoryczna (trasy, harmonogramy, alokacja zasobów, portfele inwestycyjne), chemia kwantowa i projektowanie materiałów, wybrane zadania uczenia maszynowego oraz wybrane problemy liniowo-algebraiczne.
Jeśli w systemie istnieje pojedynczy komponent, który „pożera” większość czasu obliczeniowego (np. solver tras dla floty, moduł rekomendacji, wyszukiwarka najlepszej kombinacji parametrów), to jest dobry kandydat do przyszłego przeniesienia na hybrydowe lub kwantowe podejście.
Które branże powinny inwestować w obliczenia kwantowe już teraz, a które mogą poczekać?
Wczesnymi beneficjentami są firmy, których model biznesowy opiera się na intensywnej optymalizacji lub kosztownych symulacjach: logistyka i operatorzy (trasy, harmonogramy), farmacja, chemia i materiały (symulacje cząsteczek, projektowanie leków), a także instytucje finansowe (portfele, wycena złożonych instrumentów, zarządzanie ryzykiem). Duże działy R&D często budują kompetencje kwantowe wcześniej, żeby wyprzedzić konkurencję.
Większość typowych aplikacji CRUD, systemów transakcyjnych czy serwisów webowych może pozostać przy klasycznej infrastrukturze. W ich przypadku wystarczy dbać o czystą separację modułów „mózgu” systemu (np. scoring, rekomendacje, analityka zaawansowana), aby w przyszłości móc je ewentualnie podmienić na wariant hybrydowy.
Czym różni się model obwodowy od podejścia annealing / adiabatycznego w programowaniu kwantowym?
W modelu obwodowym programista buduje obwód kwantowy jako sekwencję bramek działających na kubitach. Taki obwód jest potem wykonywany na urządzeniu kwantowym lub symulatorze. Ten model stosują m.in. IBM, Google oraz większość narzędzi open-source.
W podejściu adiabatycznym / annealing (np. D-Wave) zamiast ręcznie układać bramki, koduje się problem jako funkcję energii, często w formacie QUBO. Urządzenie szuka konfiguracji zmiennych minimalizującej tę funkcję. Z perspektywy dewelopera różnica jest podobna jak między pisaniem własnego solvera a korzystaniem ze specjalizowanego silnika optymalizacyjnego.
Czy muszę znać zaawansowaną fizykę kwantową, żeby pisać kod pod komputery kwantowe?
Nie. Przydatne jest rozumienie kilku podstawowych pojęć na poziomie „inżynierskim”: kubit jako uogólnienie bitu, superpozycja, splątanie, pomiar i jego probabilistyczny charakter, a także idea obwodu kwantowego jako funkcji przetwarzającej stan wejściowy. Taka wiedza wystarcza, żeby rozpocząć pracę z Qiskit, Cirq czy Q#.
Głębsza fizyka staje się potrzebna dopiero wtedy, gdy próbujesz projektować zupełnie nowe algorytmy kwantowe lub optymalizować obwody na poziomie sprzętowym. W typowych zastosowaniach biznesowych programista korzysta z istniejących bibliotek i gotowych „klocków” algorytmicznych, podobnie jak w klasycznym ML.